
A while back, a colleague and I started brainstorming about how to actually run semi-closed experiments centered on how humans use AI chat systems. The problem is, most people use AI systems from a proprietary, closed web front end like ChatGPT, or even more tricky, a desktop or phone app. These kinds of interfaces are great user experiences, but also prevent anyone (including researchers) from managing the workflow between the AI system and, say, research project participants.
Such a project would need three things that no existing platform could provide (or so far has been willing to provide) simultaneously:
- Admin steerable multi-model support (switching between proprietary and open-source LLMs mid-session)
- Persistent conversation memory with semantic retrieval
- Full transparency into every layer of the pipeline
That last requirement is the one that matters most for research engineering. It's not enough to have a working system. A researcher needs to understand why every component works, so they can change one variable at a time and observe the results with confidence that the output is trustworthy. When a model gives an unexpected response, a researcher needs to to be able to trace the anomaly back through the workflow: the retrieved context, the memory state, and the model configuration. They need to see and control the actual token counts, analyze the retrieval similarity comparisons, examine the chunks, and the base prompt that was assembled for that specific request. Hosted solutions are black boxes. For research, you need a meticulously labeled, clear container.
Gen AI tech also moves really fast. The model that that a project uses today may be deprecated in months (often without a cooldown). Any given LLM provider will change their API eventually. Embedding dimensions may shift when you switch vendors or the embedding model is upgraded. I wanted to design an architecture where every component could be swapped without rewriting the rest of the system. Modularity isn't a nice-to-have for research code anymore.
On the reproducibility side, I also knew that this project would eventually be open source, and that other researchers would want to clone the repo, and reproduce the results.
So here's what I built: a quick and dirty FastAPI backend, Next.js frontend (forked from an open-source chat template), PostgreSQL data storage with pgvector for both relational data and vector search, and multi-provider LLM support through OpenAI and Fireworks AI. The whole thing is containerized with Docker for simiplicity, but can easily be wired up to Kubernetes.
The Architecture at a Glance
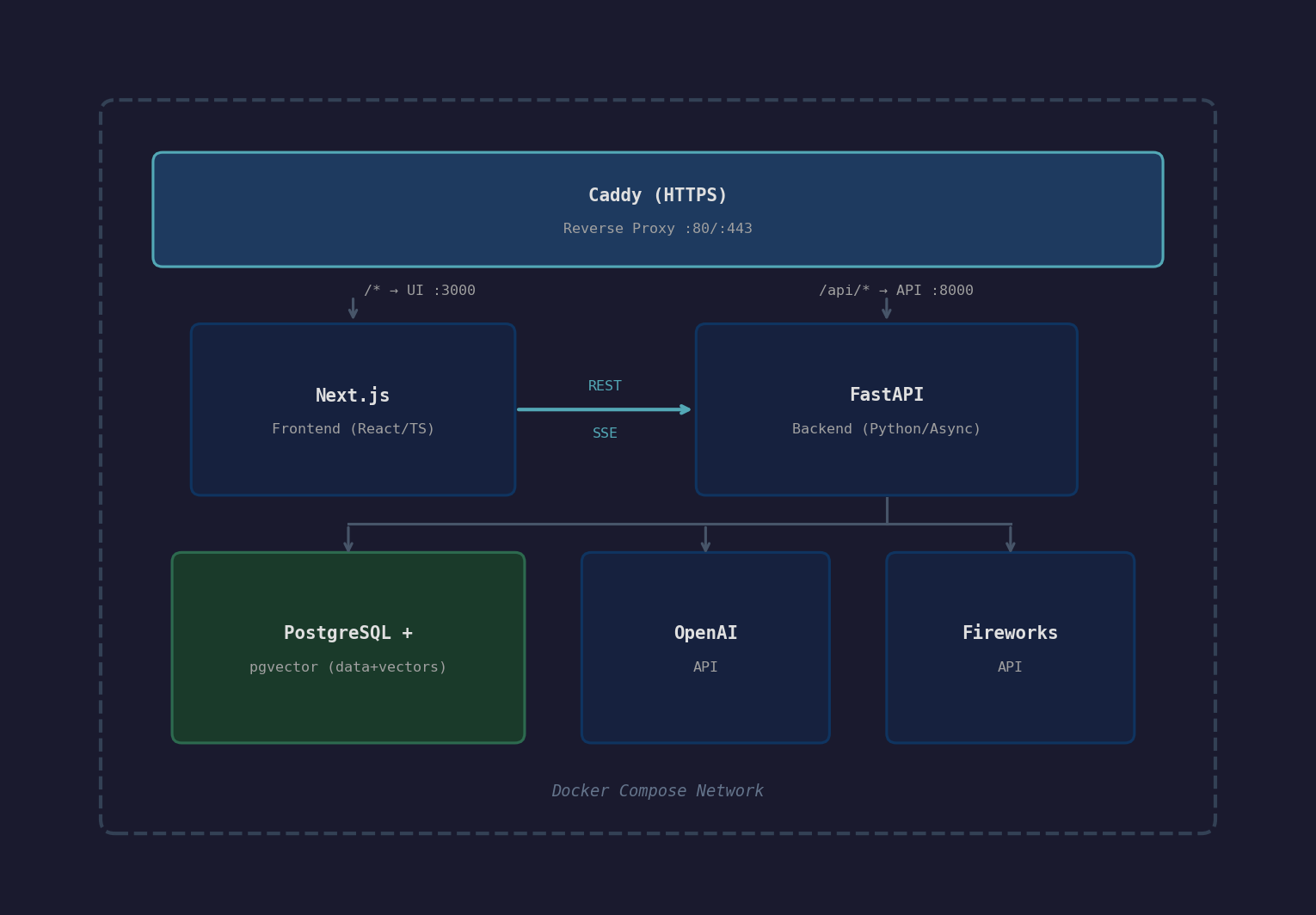
The idea here is that every boundary is something that I can easily swap out. The database could use a different vector store. The LLM providers sit behind an abstract client. The frontend talks to a REST API, not directly to any model. Caddy handles HTTPS without the application caring. This isn't a monolith.
Choosing LLM Providers: Proprietary + Open-Source
My research objective required me to compare model behavior across different architectures, model vintages and developers/labs. That's impossible if you're locked into one provider. So from day one, the system had to support both proprietary and open-source models.
I went with OpenAI for frontier capability (GPT-5 for generation, text-embedding-3-small for embeddings) and Fireworks AI for open-source model access (DeepSeek, Qwen, Llama) at lower cost. One big practical win: Fireworks serves open-source models via an OpenAI-compatible API, so the integration surface is nearly identical between the two. And from a reproducibility standpoint, open-source model weights are frozen and publicly available. Another researcher can replicate results even if a proprietary model gets updated behind the scenes.
I could've chosen a different pairing (Google/Anthropic etc.. for commercial or Groq/AWS Bedrock for OSS) but since the provider modules are already abstracted, adding addition providers or swapping existing ones would be trivial. In the end, these two simply served my research goals better.
The foundation of the whole multi-provider setup is an abstract base class that every provider implements:
from abc import ABC, abstractmethod
from typing import List, Dict, Optional, AsyncGenerator
class BaseLLMClient(ABC):
"""Every LLM provider implements this interface.
Adding a new provider means writing one class, not rewiring routes."""
def __init__(self, api_key: str, model_config: ModelConfig):
self.api_key = api_key
self.model_config = model_config
@abstractmethod
async def generate_response(
self, messages: List[Dict[str, str]], **kwargs
) -> LLMResponse:
"""Single response. Returns standardized LLMResponse regardless of provider."""
pass
@abstractmethod
async def generate_streaming_response(
self, messages: List[Dict[str, str]], **kwargs
) -> AsyncGenerator[str, None]:
"""Token-by-token streaming. Yields plain strings, not provider objects."""
pass
@abstractmethod
async def generate_embeddings(
self, texts: List[str], model: Optional[str] = None
) -> List[List[float]]:
"""Text to vectors. Provider chooses its own embedding model."""
pass
This is the cornerstone. When a new provider or model drops (and in this field, that's monthly), I write one new class and everything else stays untouched. The LLMResponse dataclass standardizes what comes back: content, model name, provider, token usage, metadata. Doesn't matter where it came from.
The Fireworks client shows what this looks like for providers that don't have an official Python SDK. It uses raw httpx for async HTTP and parses SSE streams by hand:
async def generate_streaming_response(
self, messages: List[Dict[str, str]], **kwargs
) -> AsyncGenerator[str, None]:
"""Stream tokens from Fireworks via Server-Sent Events.
Fireworks uses the OpenAI-compatible format, so we parse 'data: ' lines."""
config = self.model_config.to_dict()
config.update(kwargs)
config["messages"] = messages
config["stream"] = True
async with httpx.AsyncClient() as client:
async with client.stream(
"POST",
f"{self.BASE_URL}/chat/completions",
headers=self.headers,
json=config,
timeout=60.0,
) as response:
response.raise_for_status()
async for line in response.aiter_lines():
if line.startswith("data: "):
data_str = line[6:] # Strip the SSE prefix
if data_str.strip() == "[DONE]":
break
try:
data = json.loads(data_str)
delta = data["choices"][0].get("delta", {})
if delta.get("content"):
yield delta["content"]
except json.JSONDecodeError:
continue
Another big tradeoff here: OpenAI has an official async SDK (AsyncOpenAI) that handles streaming, retries, and error parsing. Fireworks doesn't have an equivalent, so I used httpx directly. The OpenAI client is about 15 lines for the same streaming operation. The Fireworks client is 30. That's the cost of raw HTTP, but it also means zero dependency on a third-party SDK that might lag behind API changes. For a well-maintained SDK like OpenAI's, it's worth using. For smaller providers, raw HTTP gives me more control and fewer surprises.
There's also an embedding asymmetry worth calling out. OpenAI provides 'text-embedding-3-small' (1536 dimensions) or 'text-embedding-3-large' (3072 dimensions) through their API. For Fireworks, the client falls back to local sentence-transformers if the provider's embedding endpoint isn't available. This means embedding dimensions can differ between providers, which matters for the vector database schema. I decided to standardize on 1536 dimensions (mirroring OpenAI's smaller model) and use OpenAI for all embedding generation, even when the chat model is running on Fireworks.
The Database Decision: PostgreSQL + pgvector
When people hear "vector database," they immediately think Pinecone, Qdrant, Weaviate etc... I didn't use any of them. I just added the pgvector extension to PostgreSQL and stored vectors alongside my relational data.
Why? Honestly, I didn't need to. One fewer service to deploy means one fewer thing that can break, and one fewer thing a researcher cloning the repo needs to configure. pgvector gives me vector similarity search inside the same database that stores conversations, sessions, and messages. I can JOIN across them. When I'm debugging retrieval, I can query the raw embeddings, similarity scores, and source content in one SQL statement. And for a research application with thousands (not millions) of vectors, pgvector with HNSW indexing is more than sufficient.
Here's the core memory model:
from pgvector.sqlalchemy import Vector
class MemoryChunk(Base):
"""Each chunk is a piece of retrievable context with its embedding.
Vectors live alongside relational data: one database, one query language."""
__tablename__ = "memory_chunks"
id = Column(UUID(as_uuid=True), primary_key=True, default=uuid.uuid4)
content = Column(Text, nullable=False)
chunk_type = Column(String(50), nullable=False, index=True)
# 1536 dims = OpenAI text-embedding-3-small. Change this if you switch models.
embedding = Column(Vector(1536), nullable=True)
# Retrieval scoring signals
importance_score = Column(Float, nullable=True)
semantic_score = Column(Float, nullable=True)
# Scoping: who, when, which conversation
user_id = Column(String(255), nullable=True, index=True)
session_id = Column(String(255), nullable=True, index=True)
conversation_id = Column(UUID(as_uuid=True), ForeignKey("conversations.id"))
timestamp = Column(DateTime, default=datetime.utcnow, nullable=False)
__table_args__ = (
# HNSW index for approximate nearest neighbor search
Index("idx_memory_embedding", "embedding",
postgresql_using="hnsw",
postgresql_with={"m": 16, "ef_construction": 64},
postgresql_ops={"embedding": "vector_cosine_ops"}),
)
The HNSW index configuration (m=16, ef_construction=64) controls the tradeoff between index build time and search accuracy. These are reasonable defaults for research-scale data. The vector_cosine_ops operator class tells pgvector to use cosine distance, which is the standard choice for normalized embeddings. L2 is an alternative, but cosine is more intuitive (1.0 = identical, 0.0 = unrelated) and what most embedding models are optimized for.
The Vector(1536) column type comes from the pgvector SQLAlchemy integration. It stores a float array and enables the similarity operators. One line in the model definition, and a regular old PostgreSQL database does vector search.
RAG(-ish) Memory Architecture
Before writing any code for the memory system, I wrote an architecture doc. It outlined memory scopes, chunking strategies, and retrieval patterns. That document became the blueprint, and the code became the implementation.
Memory Scopes
Not all memory is created equal. A message from five minutes ago in the current conversation is way more relevant than one from last week's session. The system defines four scopes: CONVERSATION (current thread), SESSION (all conversations in a research session), USER (everything from this user), and GLOBAL (shared knowledge base). When the retriever searches for context, it pulls candidates from the right scope first, then filters and ranks from there.
The Retrieval Pipeline
The core retrieval method walks through a pretty standard pipeline: collect candidates by scope, filter, search, rerank, return.
async def search_memory(
self,
query: MemoryQuery,
conversation_memory: ConversationMemory,
global_chunks: Optional[List[MemoryChunk]] = None,
) -> MemoryResult:
"""Full retrieval pipeline: scope → filter → search → rerank → return."""
# Step 1: Embed the query if we don't have an embedding yet
if not query.query_embedding:
embeddings = await self.llm_client.generate_embeddings([query.query_text])
query.query_embedding = embeddings[0] if embeddings else []
# Step 2: Collect candidates from the right scope
candidate_chunks = self._collect_candidate_chunks(
query, conversation_memory, global_chunks or []
)
# Step 3: Filter by time range and content criteria
candidate_chunks = self._apply_temporal_filters(query, candidate_chunks)
candidate_chunks = self._apply_content_filters(query, candidate_chunks)
# Step 4: Semantic similarity search (cosine distance)
similar_chunks = await self._semantic_search(query, candidate_chunks)
# Step 5: Rerank with multiple signals (not just cosine)
reranked_chunks = self._rerank_chunks(query, similar_chunks)
# Step 6: Take top-k and build context text
final_chunks = reranked_chunks[:query.max_results]
context_text = self._generate_context_text(final_chunks)
return MemoryResult(
chunks=final_chunks,
total_searched=len(candidate_chunks),
context_text=context_text,
)
Reranking with Multiple Signals
Pure cosine similarity gets maybe 80% of the way there. Reranking with additional signals closes the gap. The reranker combines three scores:
def _rerank_chunks(self, query, chunk_similarity_pairs):
"""Combine semantic similarity with recency and importance.
Weights: 60% semantic, 20% recency, 20% importance."""
current_time = datetime.utcnow()
scored_chunks = []
for chunk, similarity_score in chunk_similarity_pairs:
# Semantic similarity is the primary signal (60% weight)
total_score = similarity_score * query.boost_semantic
# Recency: exponential decay over one week (20% weight)
if chunk.timestamp:
hours_old = (current_time - chunk.timestamp).total_seconds() / 3600
recency_score = max(0, 1 - (hours_old / 168)) # 168 hours = 1 week
total_score += recency_score * query.boost_recent * 0.1
# Importance: metadata-derived score (20% weight)
if chunk.importance_score:
total_score += chunk.importance_score * query.boost_important * 0.1
scored_chunks.append((chunk, total_score))
scored_chunks.sort(key=lambda x: x[1], reverse=True)
return [chunk for chunk, _ in scored_chunks]
Why not just cosine similarity? Because in a conversation, recency matters. A lot. A chunk from five minutes ago about "the database schema" is almost certainly more relevant than a highly similar chunk from three days ago about a totally different schema. The recency boost captures that. The importance score captures structural signals: chunks with more entities, keywords, or question marks tend to be more informative.
Conversation Summarization
Long conversations create a context window problem. I can't stuff 200 messages into a prompt. The summarizer handles this with progressive summarization: when a conversation crosses a message threshold, it generates a summary and then updates it incrementally as new messages come in.
class ConversationSummarizer:
"""Progressive summarization keeps context window manageable
without losing conversation history."""
def __init__(self, llm_client: BaseLLMClient):
self.llm_client = llm_client
async def summarize_conversation(
self,
messages: List[Dict[str, Any]],
existing_summary: str = "",
max_summary_length: int = 200,
) -> str:
# Format the last 10 messages for summarization
recent_text = "\n".join([
f"{msg.get('role', 'unknown')}: {msg.get('content', '')}"
for msg in messages[-10:]
])
# If updating, provide the existing summary as context
if existing_summary:
prompt = (
f"Update this conversation summary with the new messages:\n\n"
f"Current Summary:\n{existing_summary}\n\n"
f"New Messages:\n{recent_text}\n\n"
f"Updated summary in {max_summary_length} words or less:"
)
else:
prompt = (
f"Summarize this conversation in {max_summary_length} words or less,"
f" focusing on key points and decisions:\n\n{recent_text}"
)
response = await self.llm_client.generate_response(
[{"role": "user", "content": prompt}],
max_tokens=max_summary_length + 50
)
return response.content.strip()
The progressive approach matters. Instead of re-summarizing the entire conversation from scratch each time (expensive and lossy), it just updates the existing summary with new information. Same idea as keeping running notes during a long meeting.
The API Layer: FastAPI and Async All the Way Down
FastAPI was a pretty obvious choice for the backend. Native async support is critical for an LLM application because the workload is almost entirely I/O bound: waiting on model responses, database queries, and embedding generation. Flask or Django would have required bolting on async support. FastAPI has it built in.
The other benefits add up too. Automatic OpenAPI docs mean every endpoint is self-documenting (important when other researchers eventually need to use the API). Pydantic validation catches malformed requests before they hit the LLM clients. And dependency injection keeps provider management clean.
Here's the streaming endpoint, which is probably the most technically interesting part of the API:
@router.post("/stream")
async def chat_stream(
request: StreamingChatRequest,
background_tasks: BackgroundTasks,
db: Session = Depends(get_database),
openai_client: OpenAIClient = Depends(get_openai_client),
fireworks_client: FireworksClient = Depends(get_fireworks_client),
memory_manager: PersistentMemoryManager = Depends(get_memory_manager),
):
"""Stream chat response via Server-Sent Events.
FastAPI's dependency injection wires up the right provider automatically."""
# Select the right LLM client based on model_id
llm_client = resolve_client(request, openai_client, fireworks_client)
async def generate():
full_content = ""
# Retrieve memory context before generating
memory_context = await memory_manager.get_context_for_response(
request.conversation_id, request.message
)
messages = build_messages(request, memory_context)
# Stream tokens as SSE events
async for chunk in llm_client.generate_streaming_response(messages):
full_content += chunk
yield f"data: {json.dumps({'chunk': chunk})}\n\n"
# Persist the complete message after streaming finishes
save_messages_to_db(db, request, full_content)
yield f"data: {json.dumps({'done': True})}\n\n"
return StreamingResponse(
generate(),
media_type="text/event-stream",
headers={"Cache-Control": "no-cache", "X-Accel-Buffering": "no"}
)
The flow: FastAPI's dependency injection provides the right clients, an async generator yields SSE-formatted chunks as the LLM produces them, and the full response gets persisted to the database after streaming finishes. The X-Accel-Buffering: no header tells Caddy (and nginx, if I ever switch) not to buffer the response. Without it, the proxy would collect the entire stream before sending it to the client, which defeats the whole purpose.
The dependency injection for dynamic LLM client selection is where the modularity really comes together:
def create_llm_client_for_session(
provider: str,
model_config_dict: Dict[str, Any],
settings: Settings
):
"""Route to the right provider based on session configuration.
Changing providers is a config change, not a code change."""
model_name = model_config_dict.get('model')
temperature = model_config_dict.get('temperature', 0.7)
max_tokens = model_config_dict.get('max_tokens', 2000)
config = ModelConfig(
model_name=model_name,
temperature=temperature,
max_tokens=max_tokens
)
if provider == "openai":
return OpenAIClient(api_key=settings.OPENAI_API_KEY, model_config=config)
elif provider == "fireworks":
return FireworksClient(api_key=settings.FIREWORKS_API_KEY, model_config=config)
else:
raise ValueError(f"Unknown provider: {provider}")
Each research session can be configured with a different model and provider. The API routes don't know or care which provider is active. They just call generate_response() or generate_streaming_response() on whatever BaseLLMClient they receive.
The Frontend: Forking a Chat Template
I forked the frontend from Chatbot UI, McKay Wrigley's open-source ChatGPT clone. Building a responsive chat interface with message history, streaming display, markdown rendering, and code highlighting from scratch is a lot of work and front end isn't really my forte anyway. Forking saved me probably weeks of frustrating work, and let me focus on the parts that were unique to my project.
What I changed: session management (research sessions have a start/complete lifecycle), multi-model display (showing which model generated each response), a custom API client pointing to my FastAPI backend instead of OpenAI directly, and a Zustand store for global state.
The streaming client consumes SSE from the FastAPI backend:
async sendMessageStreaming(
request: ChatRequest,
onChunk: (chunk: string) => void,
onComplete: (data: { message_id: string; conversation_id: string }) => void,
onError?: (error: string) => void
): Promise<void> {
// Use fetch + ReadableStream instead of EventSource for POST support
const response = await fetch(`${this.baseURL}/chat/stream`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(request),
})
const reader = response.body?.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader!.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() || '' // Keep incomplete line in buffer
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6))
if (data.chunk) onChunk(data.chunk)
if (data.done) { onComplete(data); return }
if (data.error) { onError?.(data.error); return }
}
}
}
}
Quick note on why this uses fetch with a ReadableStream reader instead of the browser's EventSource API: EventSource only supports GET requests. Since I need to POST chat messages with a JSON body, fetch it is. The buffer handling matters because chunks from the network can arrive mid-line, so the client accumulates them and only processes complete lines.
For global state, I went with Zustand over Redux:
export const useChatStore = create<ChatStore>()(
persist(
(set, get) => ({
sessionId: null,
isSessionActive: false,
messages: [],
selectedModel: { id: 'gpt-5', name: 'GPT-5', provider: 'openai' },
isLoading: false,
sendMessage: async (content: string) => {
const { sessionId, currentConversationId, selectedModel } = get()
set({ isLoading: true })
// Optimistic update: show user message immediately
const userMessage = { role: 'user', content, id: uuidv4() }
set(state => ({ messages: [...state.messages, userMessage] }))
// Send to backend and wait for response
const response = await apiClient.sendMessage({
message: content,
session_id: sessionId,
model_id: selectedModel.id,
model_provider: selectedModel.provider,
})
// ... handle response
},
setSelectedModel: (model) => {
set({ selectedModel: model })
},
}),
{ name: 'chat-store', partialize: (state) => ({ sessionId: state.sessionId }) }
)
)
Zustand is dramatically simpler than Redux for something like this. No middleware chains, no action creators, no boilerplate. The persist middleware saves the session ID to localStorage so refreshing the page doesn't lose the active session. The partialize option controls what gets persisted (I definitely don't want the full message history in localStorage).
Deployment: Docker Compose and Caddy
My deployment goal was straightforward: docker-compose up should be the entire setup. No manual database provisioning, no external service dependencies beyond API keys. Here's the compose file:
services:
db:
image: pgvector/pgvector:pg16
restart: unless-stopped
environment:
POSTGRES_DB: ${DB_NAME:-llm_research}
POSTGRES_USER: ${DB_USER:-postgres}
POSTGRES_PASSWORD: ${DB_PASSWORD:?DB_PASSWORD is required}
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${DB_USER:-postgres}"]
interval: 5s
retries: 5
api:
build: { context: ., dockerfile: Dockerfile.api }
depends_on:
db: { condition: service_healthy }
environment:
DB_HOST: db
OPENAI_API_KEY: ${OPENAI_API_KEY:?OPENAI_API_KEY is required}
FIREWORKS_API_KEY: ${FIREWORKS_API_KEY:-}
healthcheck:
test: ["CMD", "python", "-c",
"import urllib.request; urllib.request.urlopen('http://localhost:8000/health')"]
interval: 10s
start_period: 30s
ui:
build:
context: .
dockerfile: Dockerfile.ui
args:
NEXT_PUBLIC_API_BASE_URL: ${PUBLIC_URL:-http://localhost:8000}/api
depends_on: [api]
caddy:
image: caddy:2-alpine
ports: ["80:80", "443:443"]
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy_data:/data
depends_on: [api, ui]
volumes:
pgdata:
caddy_data:
A few things worth calling out. The pgvector/pgvector:pg16 image comes with the pgvector extension pre-installed, so no manual CREATE EXTENSION step. The ? syntax in environment variables (DB_PASSWORD:?) makes Docker Compose fail fast with a clear error if required variables are missing (much better than a cryptic crash ten seconds later). Health checks ensure services start in the right order: database healthy before the API starts, API healthy before the UI connects.
Why Caddy over nginx? Automatic HTTPS with Let's Encrypt, out of the box. The Caddyfile for this setup is about 10 lines. The equivalent nginx config plus certbot setup is 50+ lines and a cron job. For a research deployment, that's an easy call.
There's a .env.example that documents every configuration variable. The workflow for someone cloning the repo: copy .env.example to .env, fill in the API keys, docker-compose up. Done.
What I Deliberately Left Out (and Built Later)
The first version was intentionally scoped down. I knew there were capabilities I'd eventually want, but I also knew that the modularity baked in from the start would let me add them later without rewriting the foundation. Here's what got cut, why, and what happened when the next project demanded it.
The big paradigm shift: from chat to agentic.
The initial platform was purely conversational: user sends message, model responds. The next project needed something fundamentally different. Agents that could use tools, reason through multi-step problems, reflect on their own output, and orchestrate across providers. That shift from "chat" to "agentic" changed everything about the design center. But because the first system was modular (provider-agnostic clients, scoped memory, clean API boundaries), the transition was an evolution, not a rewrite.
Multi-provider orchestration with intelligent routing. V1 used manual model assignment per session. Later, I needed automatic provider selection based on capabilities, cost, and reliability, with circuit breakers, rate limit detection, and automatic fallback across five-plus providers (OpenAI, Anthropic, Fireworks, Ollama, HuggingFace). Why skip it initially? The research protocol controlled model assignment. Dynamic routing would have been a confounding variable, not a feature.
Tool use and code execution. V1 was pure conversation, no tools. Later: a full tool framework with web browsing (Playwright), sandboxed code execution, multi-provider web search, data analysis, and document analysis. An extensible ToolManager with execution queues, result caching, and timeout management. I skipped it because the research focused on conversational interaction. Tools would have introduced uncontrolled variance in the experimental design.
Reasoning and reflection engines. V1 was direct prompt-to-response. Later: Chain-of-Thought, Tree-of-Thought, iterative refinement. A full reflection system with self-evaluation, confidence scoring, and automatic correction. The system can evaluate its own responses across multiple dimensions before sending them. I skipped it because the added latency and complexity would have obscured what I was trying to measure.
Hybrid search (semantic + keyword with Reciprocal Rank Fusion). V1 was pure semantic search via pgvector cosine similarity. Later: BM25 keyword search combined with vector search using Reciprocal Rank Fusion, plus a dedicated vector database (Qdrant) for scale. I skipped it because pgvector was plenty for conversational memory retrieval at research scale. When the document corpus grew by 10x, I needed something more serious.
Enterprise encryption and privacy controls. V1 had standard database security with JWT auth. Later: field-level encryption, data retention policies, privacy scheduling, audit logging. I skipped it because the initial deployment was behind institutional access controls. When the platform expanded to more users, the security model had to expand with it.
The pattern across all of these is the same: build what the current project needs, not what you think the next one might. The abstractions I invested in early (provider-agnostic clients, memory scopes, clean API boundaries) made each of these additions possible without a rewrite. Scope discipline isn't about being unambitious. It's about getting the foundation right so I can actually move fast later.
Wrapping Up
The goal of this work was to build an LLM chat ecosystem where I could see through every wall. That kind of transparency is what makes iterative experimentation possible, and I was suprised that I had to build out a good bit of the infrastructure out myself to get there.
That said, the resulting modularity paid off in ways that I didn't expect at the start. When a new model drops that I want to test, it's one class and a config entry, not a full rewrite. When my next project needed tools and reasoning instead of pure conversation, the provider layer, memory system, and API structure carried over directly. So despite the work, I'm happy!
The full adapted code derived from the above process will be on GitHub when the associated research paper is published.